Data delays, fragmented information, and manual processing bottlenecks often hinder businesses from revealing actionable insights. Traditional ETL methods struggle to keep up with the velocity and volume of today’s data needs, leading to inefficiencies and lost opportunities.
Apache Kafka, a distributed event streaming platform, has revolutionized how organizations manage real-time data integration. With Kafka ETL, businesses can move beyond outdated batch processes to implement scalable, fault-tolerant pipelines that handle data in motion. This blog discusses building real-time ETL pipelines with Kafka, helping you understand the power of real-time data processing to drive smarter decisions and operational efficiency.
Let’s start by exploring the core components of Kafka ETL and how they work together to enable seamless data integration.
Core Components of Kafka ETL
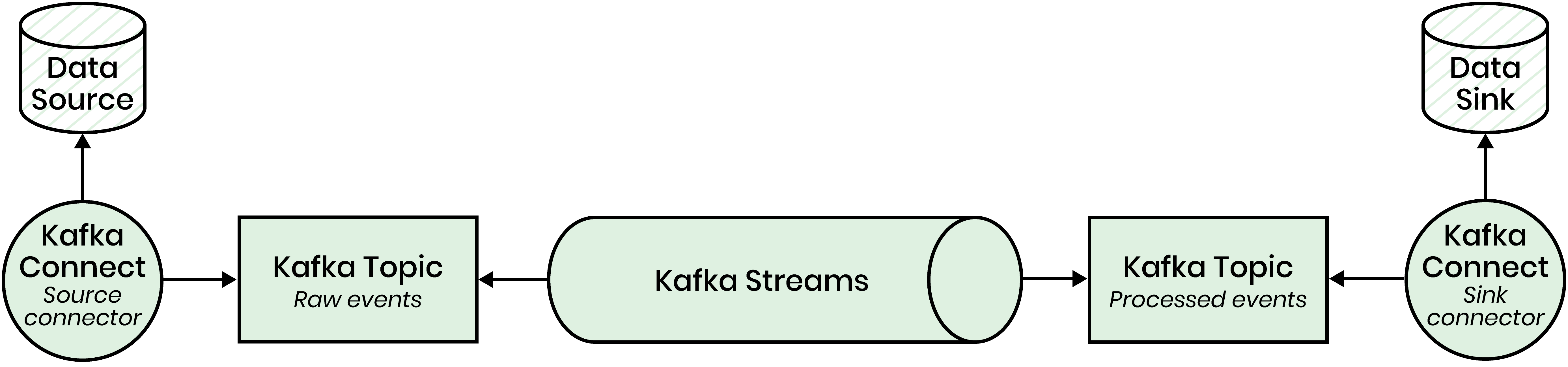
To understand how Kafka ETL works, it’s essential to grasp the key components that make it possible. Apache Kafka and its ecosystem provide the building blocks for creating efficient real-time ETL pipelines.
1. Apache Kafka
At the heart of Kafka ETL lies Apache Kafka, a distributed event streaming platform. It acts as a message broker, organizing data into topics and ensuring reliable communication between producers (data sources) and consumers (data sinks). Kafka’s ability to handle high-throughput data makes it ideal for real-time integration.
2. Kafka Connect
Kafka Connect simplifies integration by providing pre-built source connectors (to ingest data from external systems) and sink connectors (to send data to destinations like databases or analytics platforms). It reduces the need for custom code, allowing seamless connectivity between Kafka and external data systems.
3. Kafka Streams
Kafka Streams is a powerful stream-processing library that enables real-time data transformation. It allows you to perform operations like filtering, mapping, and aggregation directly within the Kafka ecosystem, ensuring low-latency processing without external dependencies.
Together, these components form the foundation of Kafka ETL, enabling businesses to build scalable and fault-tolerant data pipelines. Next, let’s explore the process of constructing a real-time ETL pipeline using Kafka.
Building a Real-Time ETL Pipeline with Kafka
Creating a real-time ETL pipeline with Kafka involves three essential steps: data extraction, transformation, and loading. Each step uses Kafka’s ecosystem to ensure seamless and efficient data integration.
Step 1: Data Extraction
Data extraction begins with capturing information from various sources like databases, APIs, or log files. Kafka Connect’s source connectors play a vital role here by ingesting data from these systems into Kafka topics. For example:
- A JDBC source connector can fetch data from relational databases.
- A REST API connector can pull data from web applications.
Step 2: Data Transformation
Once data is ingested, Kafka Streams or other stream processing tools (like Apache Flink) transform it in real-time. Typical transformations include:
- Filtering irrelevant data to reduce noise.
- Mapping and standardizing fields for consistency across datasets.
- Aggregating data for summarization or analytics purposes.
The transformed data is then written back to another Kafka topic, ready for the final stage.
Step 3: Data Loading
Finally, the processed data is sent to its destination using Kafka Connect’s sink connectors. These connectors enable seamless integration with databases, data warehouses, or analytics platforms like Elasticsearch or Snowflake.
Example Workflow
- Source: Customer data from a MySQL database is extracted via a JDBC source connector.
- Transformation: Kafka Streams standardize and enrich the data.
- Sink: The transformed data is loaded into a Snowflake data warehouse for real-time analytics.
This step-by-step approach ensures a consistent, scalable pipeline that delivers real-time insights. Next, let’s look at the advantages of Kafka ETL and why it’s a preferred choice for modern data processing.
Advantages of Kafka ETL in Real-Time Data Processing
Apache Kafka has become a cornerstone for real-time data processing, and its ETL capabilities bring several benefits to organizations. Here’s a list of advantages of Kafka ETL:
- Scalability
Kafka’s distributed architecture allows it to handle large volumes of data seamlessly. It can scale horizontally by adding more brokers to the cluster, ensuring consistent performance as your data requirements grow.
- Fault Tolerance
Kafka’s built-in replication ensures data reliability and availability. Even if a broker fails, Kafka continues to operate without data loss, making it a dependable choice for critical data pipelines.
- Low Latency
Kafka ETL excels in real-time scenarios, offering near-instantaneous data ingestion, transformation, and delivery. This low latency enables businesses to respond quickly to insights and events.
- Flexibility
Kafka integrates with a wide range of data sources and destinations through Kafka Connect. Additionally, its compatibility with tools like Apache Flink and Spark enhances its functionality for advanced use cases.
- Cost-Effectiveness
By consolidating multiple data sources into a single pipeline and automating real-time processing, Kafka reduces the need for manual intervention and minimizes operational costs.
By using these advantages, organizations can overcome traditional ETL limitations and build pipelines that deliver faster, more reliable data insights. However, implementing Kafka ETL comes with its own set of challenges, which we’ll explore in the next section.
Challenges and Considerations in Implementing Kafka ETL
While Kafka ETL offers numerous benefits, implementing it effectively requires addressing certain challenges and considerations. Understanding these factors can help you build more robust and efficient pipelines.
- Managing Data Schema Evolution: Real-time pipelines often deal with dynamic datasets where schemas change frequently. Without proper schema management, these changes can lead to errors or inconsistencies in downstream systems. Tools like Confluent Schema Registry can help mitigate this challenge by enabling schema versioning and validation.
- Operational Overhead: Running and maintaining Kafka clusters demands technical expertise. Tasks such as monitoring brokers, configuring partitions, and scaling infrastructure require significant resources and skilled personnel.
- Integration with Legacy Systems: Connecting Kafka ETL with older, less flexible systems can be challenging. Custom connectors or additional middleware may be required to bridge the gap between modern streaming architectures and legacy platforms.
- Latency in Complex Transformations: While Kafka excels at low-latency processing, complex transformations or heavy computational tasks can introduce delays. Optimizing these operations or offloading them to external tools like Apache Flink can help maintain real-time performance.
- Security and Compliance: Ensuring secure data handling in real-time pipelines is critical. Implementing encryption, authentication, and role-based access controls is necessary to protect sensitive information and comply with regulations like GDPR and HIPAA.
By anticipating and addressing these challenges, businesses can unlock the full potential of Kafka ETL. In the next section, we’ll explore how complementary tools like Hevo Data enhance Kafka’s ETL capabilities.
How Hevo Helps Overcome Kafka ETL Challenges
Hevo Data simplifies Kafka ETL by addressing its inherent challenges with a fully managed, no-code platform that enhances usability and efficiency:
- Schema Management: Hevo automates schema handling, adapting to changes in real-time without manual intervention, ensuring data consistency across pipelines.
- Reduced Operational Overhead: With Hevo, there’s no need to manage Kafka clusters. Its managed services eliminate infrastructure maintenance, allowing teams to focus on insights.
- Seamless Integration: Hevo offers 150+ pre-built connectors, bridging the gap between modern and legacy systems and ensuring smooth data integration.
- Optimized Transformations: Hevo provides built-in data transformation tools, enabling complex logic execution without compromising on latency or performance.
- Security and Compliance: Hevo ensures secure data handling with end-to-end encryption, compliance with global standards like GDPR, and role-based access controls.
By using Hevo, organizations can overcome Kafka ETL challenges while maximizing the benefits of real-time data pipelines.
Conclusion
Kafka ETL has revolutionized real-time data integration, offering low latency and fault tolerance. However, challenges such as schema evolution, operational overhead, and security concerns can complicate implementation. Hevo Data simplifies these complexities, providing a fully managed solution that enhances the efficiency of Kafka ETL pipelines.
Ready to streamline your real-time data workflows? Sign Up a trial with Hevo today and experience seamless, secure, and scalable ETL integration tailored to your business needs.
